【JVM】二十六、不再卡顿!实时分析引擎面对海量数据引发频繁Full GC的背后原因
本文将深入探讨一个实际生产环境中频繁发生Full GC的案例
1、上文案例再分析
在本次分析中,我们将深入探讨一个实际生产环境中频繁发生Full GC的案例。作为我们之前讨论过的案例的延续,我们将对一个特定的案例进行更深入的剖析。
首先,让我们回顾一下之前的案例。我们曾分析过一个日处理上亿数据的计算系统,这就是本文所要深入分析的“每日百亿数据量的实时分析系统”。
2、揭开日处理上亿数据系统的神秘面纱
这个系统的设计初衷是处理大规模的数据,每天需要处理的数据量达到数亿条记录。简而言之,这个系统的核心功能是从MySQL数据库以及其他数据源中持续抽取大量数据,并将其加载到自身的JVM内存中,以便进行高效的计算处理。
如下图所示。
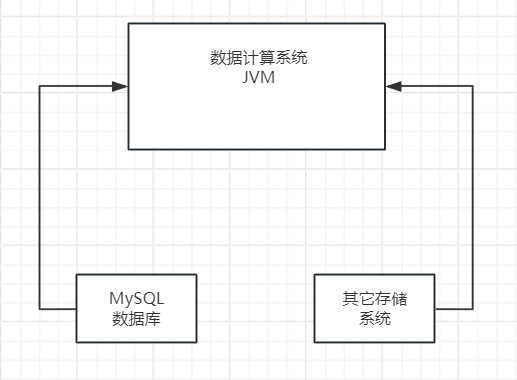
这个数据计算系统是一个高效且持续运行的系统,它通过SQL语句和其他方法,从各种数据存储中提取数据到内存中进行计算。在生产环境中,每分钟大约需要执行500次数据提取和计算的任务。
由于这是一个分布式系统,因此在生产环境中部署了多台机器以分担负载。每台机器大约每分钟负责执行100次数据提取和计算的任务。
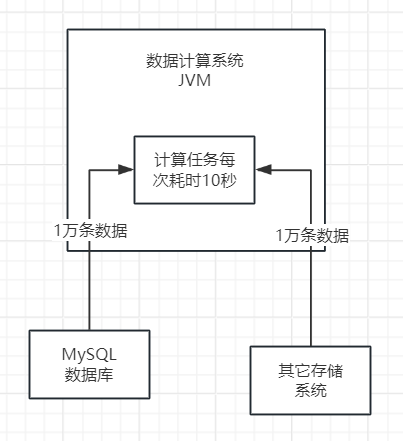
每次任务中,系统会提取大约1万条数据到内存中进行计算。平均来说,每次计算大约需要耗费10秒钟的时间。
每台机器的配置是4核8G,其中JVM内存分配了4G。在JVM内存中,新生代和老年代分别占用了1.5G的内存空间。这样的配置确保了系统的稳定运行和高效计算。
大家看下图。
3、你的新生代系统多久将被塞爆?
为了评估系统在多长时间内会填满新生代内存,我们首先需要明确一些核心数据。
假设系统中每台机器上部署的实例,每分钟执行100次数据计算任务,每次处理1万条数据,耗时10秒。接下来,我们需要估算这1万条数据所占用内存的大小。
由于每条数据较大,平均含有20个字段,我们可以假设每条数据大小约为1KB。因此,一次计算任务涉及的1万条数据大约对应了10MB的内存空间。
现在,让我们考虑新生代内存的分配情况。如果新生代按照8:1:1的比例划分Eden区和两个Survivor区,则可以推算出Eden区大约有1.2GB,每个Survivor区大约有100MB。如下图。
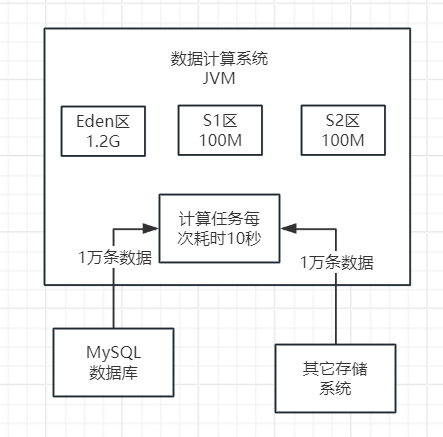
根据当前内存大小,我们可以发现,每次执行计算任务时,在Eden区会分配大约10MB的对象。如果每分钟执行约100次计算任务,那么大约一分钟后,Eden区将被对象填满,达到饱和状态。因此,可以得出结论,在新生代的Eden区中,大约1分钟左右,它就会快速被占满。
4、了解在Minor GC过程中哪些对象会被重新安置
在当前的假设中,新生代的Eden区在1分钟后已经全部被对象填满。在继续执行计算任务的过程中,必然会触发Minor GC来回收一部分垃圾对象。
在上篇文章中,我们已经讨论了在执行Minor GC之前会进行的检查。首先,我们需要确认老年代的可用内存空间是否大于新生代的所有对象。
根据下图,我们可以看到,当前老年代是空的,大约有1.5G的可用内存空间。而新生代的Eden区,我们可以估计它有大约1.2G的对象。
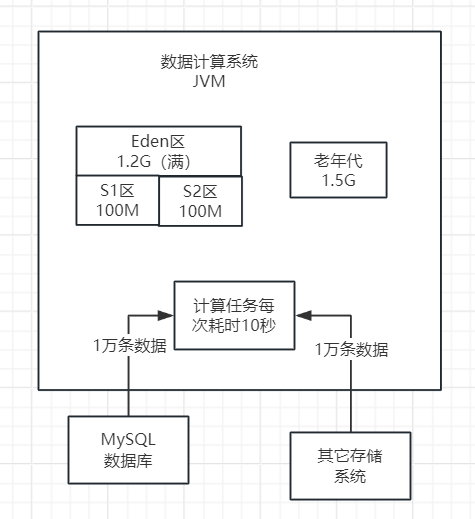
在当前的内存模型中,我们观察到老年代的可用内存空间为1.5GB,而新生代中的对象总和达到了1.2GB。假设在一次Minor GC操作之后,所有的对象都幸存下来,这些对象仍然能够被安置在老年代中。因此,在这种情况下,系统将直接执行Minor GC。
现在让我们来考虑Eden区中有多少对象是仍然存活的,并且无法被垃圾回收。
回顾我们之前提到的一个情况,每个计算任务需要处理1万条数据,耗时10秒钟。假设目前有80个计算任务已经完成,但还有20个计算任务正在处理中,这20个任务总共涉及200MB的数据。
因此,在这200MB的数据中,对象仍然是活跃的,无法被垃圾回收。除此之外,还有1GB的对象是可以被垃圾回收的。大家看下图。
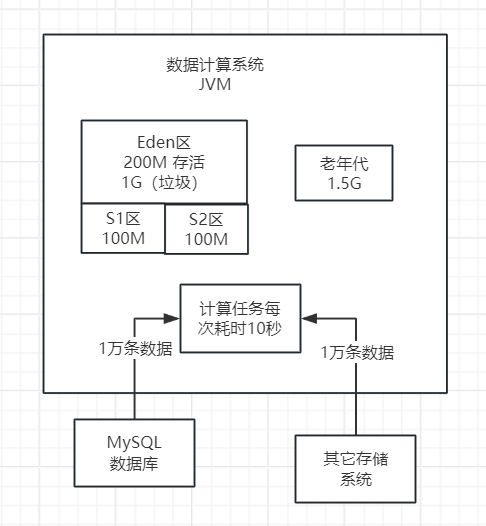
一次Minor GC将能够回收1GB的内存空间。然而,由于每个Survivor区的实际容量只有100MB,因此无法容纳200MB的对象。为了解决这个问题,会触发空间担保机制,使这200MB的对象直接进入老年代区域,占用其中的200MB内存空间。最后,Eden区将被清空。大家看下图。
5、识别老年代满载的关键时刻
那么,我们来思考一下,这个系统运行多久后,老年代会被填满呢?
根据之前的计算,每分钟都会进行一次循环。在每个循环中,新生代的Eden区会被填满,然后触发一次Minor GC。每次Minor GC之后,大约有200MB的数据会进入老年代。
那么,我们可以设想一下,如果系统已经运行了2分钟,那么此时老年代已经被占用了400MB的内存,只剩下1.1GB的可用内存。在这种情况下,当第3分钟结束时,系统再次进行Minor GC,它会进行哪些检查呢?如下图:
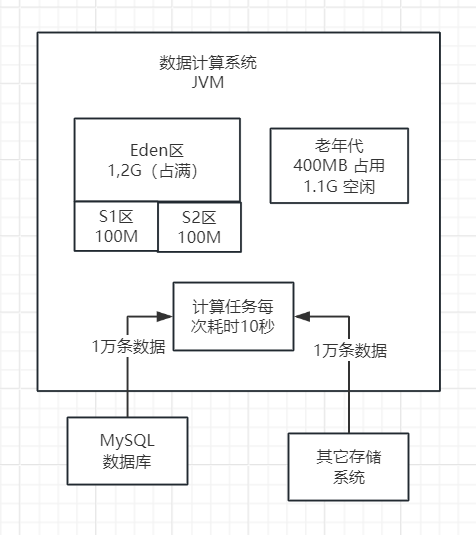
在垃圾回收过程中,首先会检查老年代的可用空间是否大于新生代所有对象的总和。
假设当前老年代的可用空间为1.1GB,而新生代的所有对象总和为1.2GB。如果假设在一次Minor GC(垃圾回收)之后,新生代的所有对象都存活下来,那么老年代将无法容纳这些对象。在这种情况下,我们需要检查一个参数是否被启用。
这个参数是“-XX:-HandlePromotionFailure”。通常情况下,这个参数是会被启用的。如果该参数被启用,那么将会进行第二步检查,即检查老年代的可用空间是否大于历次Minor GC后进入老年代的对象的平均大小。
我们已经知道,大约每分钟会执行一次Minor GC,每次大约有200MB的对象会进入老年代。因此,对于当前的1.1GB的老年代空间,它是大于每次Minor GC后平均200MB对象进入老年代的大小。所以我们可以推断,在本次Minor GC后,大概还会有200MB的对象进入老年代,而1.1GB的可用空间是足够的。
因此,系统会安心地执行一次Minor GC,然后再次有200MB的对象进入老年代。
然而,转折点出现在运行了大约7分钟后。在这期间,已经执行了7次Minor GC,大约有1.4GB的对象进入了老年代,这使得老年代的剩余空间减少到不足100MB,几乎达到了满载状态。如下图。
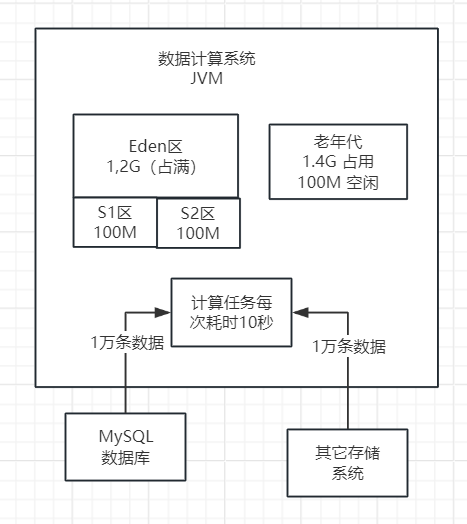
6、精确掌握Full GC的触发时机
在程序运行至第8分钟时,新生代的内存空间再次被填满。在执行Minor GC之前,系统进行了一次检查,发现老年代的剩余内存空间仅为100MB,这比每次Minor GC后进入老年代的200MB对象要小。在这种情况下,系统会直接触发一次Full GC。
Full GC的主要任务是回收老年代中的垃圾对象。假设在此时,老年代的1.4G内存空间中,全部都是可以回收的对象,那么Full GC会一次性地将这些对象进行回收,从而释放内存空间。如下图。
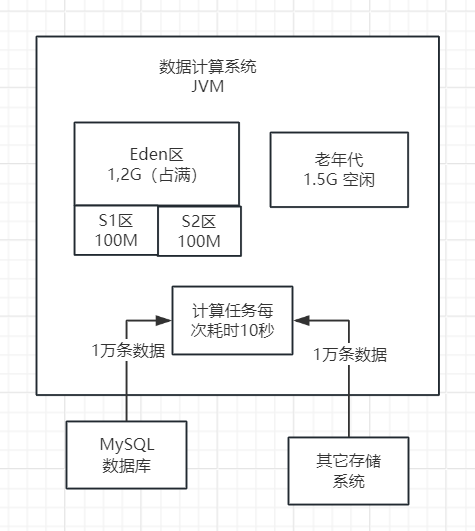
然后接着就会执行Minor GC,此时Eden区情况,200MB对象再次进入老年代,之前的Full GC就是为这些新生代本次Minor GC要进入老年代的对象准备的,如下图。
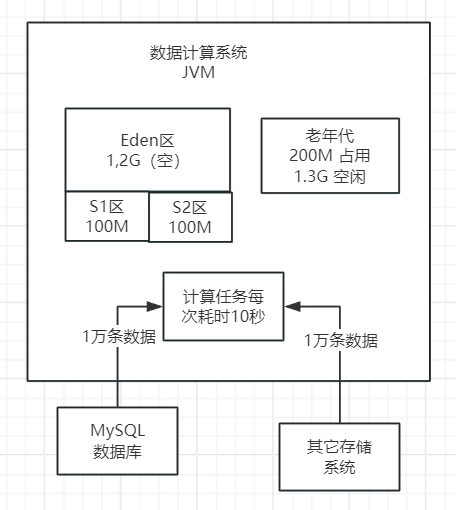
在当前的运行模型下,系统频繁触发Full GC,平均每7到8分钟就会执行一次。这种高频率的垃圾回收对性能产生了显著影响。全量垃圾回收通常速度较慢,这会导致整体性能下降。
7、揭秘JVM调优的终极技巧!
通过这个案例,相信大家在结合图示的引导下,已经对新生代与老年代的协同运作有了更深入的了解。我们探讨了何时会触发Minor GC和Full GC,以及在何种情况下会导致这两种GC频繁发生。
对于这个系统,优化其实是相对简单的。作为一个数据计算系统,每次执行Minor GC时,总会有一部分数据尚未计算完成。根据现有的内存模型,最大的问题出现在Survivor区域无法容纳所有存活的对象。
为了解决这个问题,我们对生产环境进行了调整,增加了新生代的内存比例。在一个大约3GB的堆内存中,我们分配了2GB给新生代,1GB留给老年代。这样一来,Survivor区大约有200MB的空间,足以容纳每次Minor GC后仍然存活的对象。如下图所示。
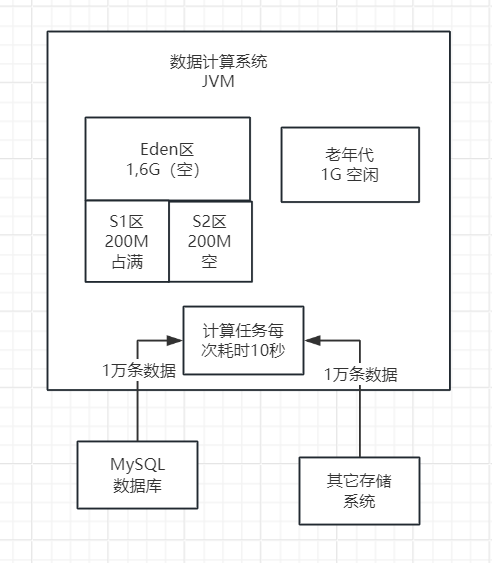
在每次执行Minor GC操作后,我们可以将200MB的存活对象放入Survivor区域。这样一来,当进行下一次Minor GC时,这些在Survivor区域中的对象所对应的计算任务应该已经完成,因此它们都可以被安全地回收。
比如,假设Eden区域中有1.6GB的空间被完全占用,而在Survivor1区域中,有200MB的存活对象是上一次执行Minor GC后保留下来的。如下图。
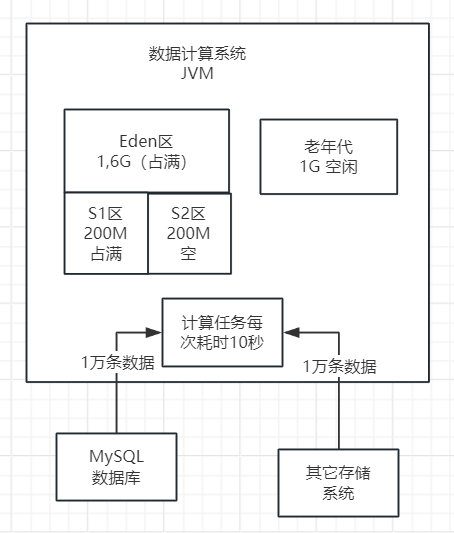
然后此时执行Minor GC,就会把Eden区里1.4GB对象回收掉,Survivor1区里的200MB对象也会回收掉,然后Eden区里剩余的200MB存活对象会放入Survivor2区里,如下图。
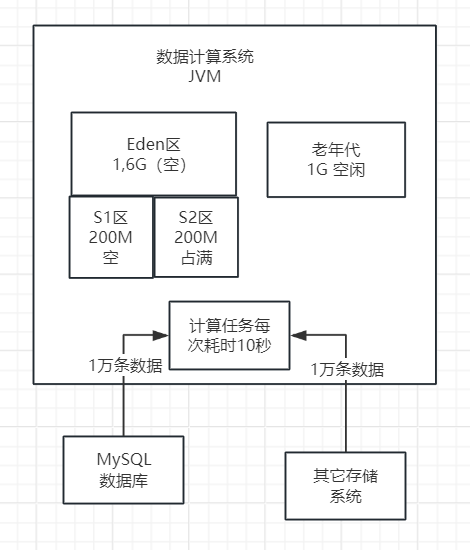
以此类推,基本上就很少对象会进入老年代中,老年代里的对象也不会太多的。
通过这个分析和优化,定时我们成功的把生产系统的老年代Full GC的频率从几分钟一次降低到了几个小时一次,大幅度提升了系统的性能,避免了频繁Full GC对系统运行的影响。
经过这样的分析和优化,我们成功降低了生产系统中老年代对象的数量。由于老年代中的对象数量减少,进入老年代的对象也变得非常有限。
通过这些措施,我们成功地将生产系统的老年代Full GC的频率从几分钟一次显著降低到了几个小时一次。这一改进极大地提升了系统的性能,有效地避免了频繁的Full GC对系统运行的影响。
8、普通系统如何优雅地承载十倍工作量?
当工作负载扩大10倍时,根据上图,我们会发现每秒钟需要将100MB的数据加载到内存中。对于1.6G的Eden区域来说,10多秒就会迅速被填满,从而触发Young GC。
然而,正如之前所提到的,每次将一批数据加载到内存中,通常需要超过10秒的时间才能完成计算。在计算完成之前,这些数据无法被回收。因此,如果你每10多秒就触发一次Young GC,那么可能导致的后果是,此时可能只能回收几百MB的垃圾,而可能有1GB的对象无法被回收。请大家仔细理解这个概念。
这种情况下,每隔10多秒就有1GB的数据进入老年代,而老年代的空间也仅有1GB左右。即使你勉强能够放下这些数据,那么下一次过10多秒后,又会放入1GB的对象到老年代。这时,必然会提前触发Full GC来回收老年代中的1GB对象,然后再让你把这次Young GC后存活的1GB对象放入老年代。
这就是我们当时遇到的真实生产场景。基本上,一台4核8G的机器每分钟要触发二三次Full GC,这对系统性能造成了巨大的影响,实在是令人担忧。
9、如何榨干大内存机器的性能潜力!
针对这个问题,因为考虑到这是一个计算类的系统,对内存的需求非常大,所以已经将每台机器的配置升级为16核32G的高配置。
这样的配置下,Eden区域的空间会扩大到原来的10倍,例如,可以达到16GB。在这样的情况下,如果每秒向内存中加载100MB的数据进行计算,大约需要2分钟才会触发一次Young GC。由于降低了Young GC的频率,每次触发Young GC时,存活的对象大概只有几百MB,不会超过1GB。
在这种情况下,我们为每个Survivor区域分配了2GB的内存,所以每次Young GC后,存活的对象可以轻松地放入Survivor区域中,而不会进入老年代。通过提升机器配置的方式,我们成功地解决了频繁触发Young GC和Full GC的问题。
许多同学可能会问,对于大内存的机器,是否需要使用G1来减少每次Young GC的停顿时间?答案是不需要。因为这个系统是后台自动进行计算的,不是直接面向用户的,所以即使每2分钟进行一次Young GC,每次停顿1秒钟,对系统的影响也几乎可以忽略不计。
10、本文总结
这篇文章继续以实际案例为基础,深入探讨了在处理1亿数据量级的系统时,当系统部署在配置为4核8GB内存的机上,为何频繁出现Full GC(全垃圾回收)现象,以及我们应如何进行优化。接着,文章进一步分析了在处理10亿数据量级的系统时,同样部署在4核8GB的机器上,Full GC的出现将会有多么严重,并探讨了如何通过提升机器配置来进行优化。
通过仔细阅读这个案例,我们可以深入理解Full GC问题。一旦我们彻底理解了这一点,就能够有效解决频繁发生的Full GC问题。