【JVM】二十五、技术深挖:优化BI系统以稳定支撑每秒10万请求量,解决Young GC难题
本文将重点讨论JVM频繁垃圾回收对系统性能的负面影响
1、前文回顾
接下来,我们将重点讨论JVM频繁垃圾回收对系统性能的负面影响。为了深入理解这一主题,我们首先分析了JVM进行垃圾回收的具体场景以及其背后的原理。接着,我们对各种垃圾回收相关术语进行了概念梳理,并解释了它们的触发时机。
现在,我们将通过实际案例来进一步强调频繁垃圾回收所带来的性能问题,帮助大家更加深刻地认识到,如果JVM频繁地进行垃圾回收,将会对我们的系统性能造成怎样的影响。
2、揭开服务百万商家的BI系统神秘面纱!
首先,我想向大家介绍一个服务于百万级商家的BI(商业智能)系统。简单来说,假设你是一个平台运营者,有数十万甚至上百万的商家在你的平台上进行生意,他们会使用你提供的平台系统。在这个过程中,势必会产生大量的数据。基于这些数据,我们需要为商家提供一些数据报表,例如:每个商家每天有多少访客?有多少交易?付费转化率是多少?当然,实际情况会比这简单几句话复杂得多,这里我们只是简单介绍一下概念。因此,此时就需要一套BI系统。
所谓BI,英文全称是“Business Intelligence”,也就是“商业智能”。它的主要功能就是收集商家日常经营的数据进行分析,并将各种数据报表展示给商家,让商家能够更好地了解自己的经营状况,然后让老板能够“智能”地调整经营策略,从而提升业绩。
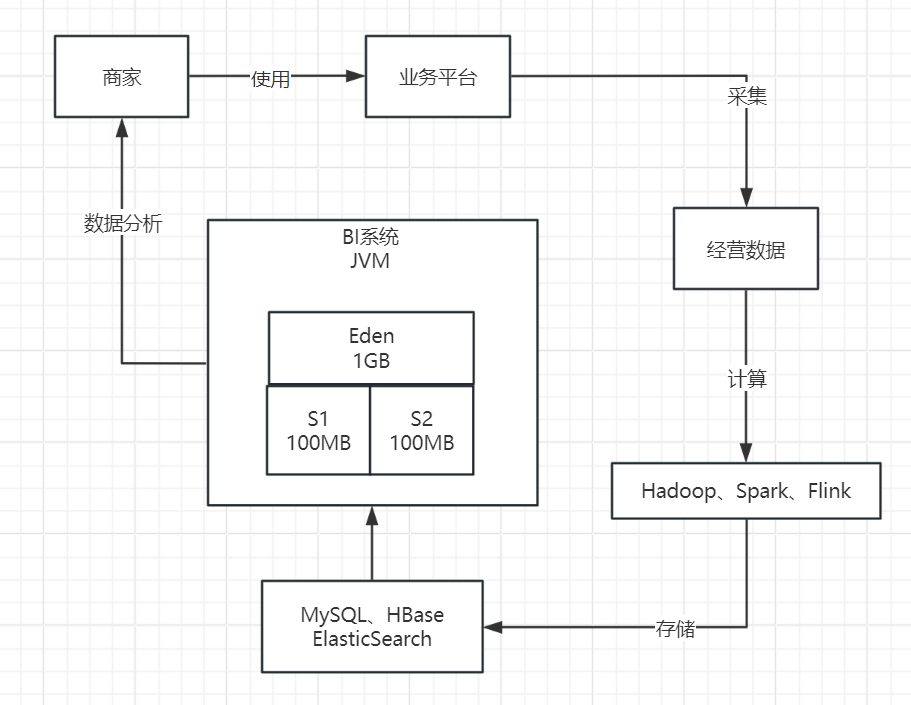
所以,这样的一个BI系统的大致运行逻辑如下:首先,从我们提供给商家日常使用的一个平台上,会采集出很多商家日常经营的数据。如下图所示。
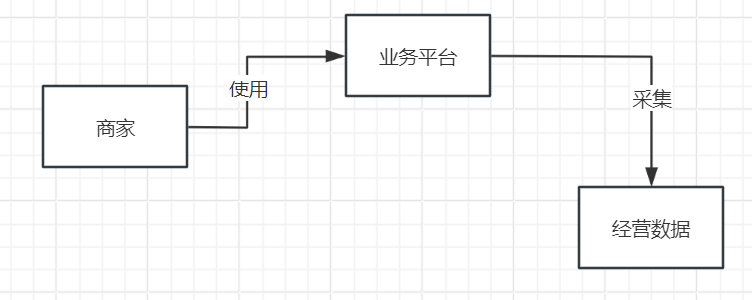
接着就可以对这些经营数据依托各种大数据计算平台,比如Hadoop、Spark、Flink等技术进行海量数据的计算,计算出来各种各样的数据报表,如下图所示。
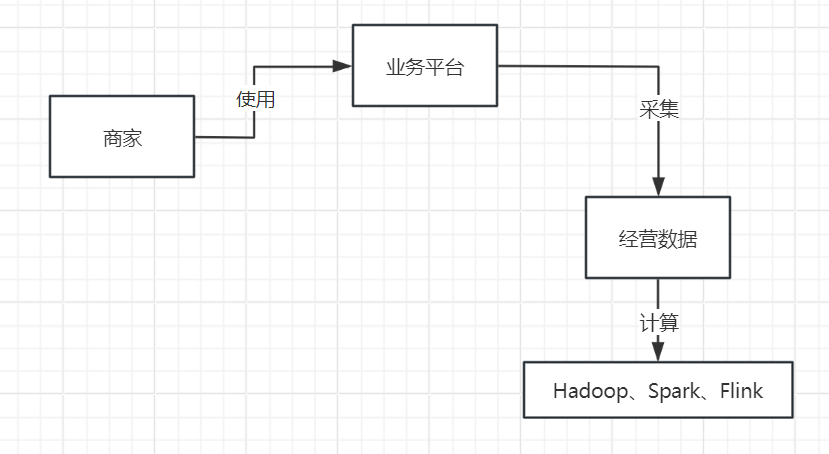
然后我们需要将计算好的各种数据分析报表都放入一些存储中,比如说MySQL、Elastcisearch、HBase都可以存放类似的数据,如下图所示。
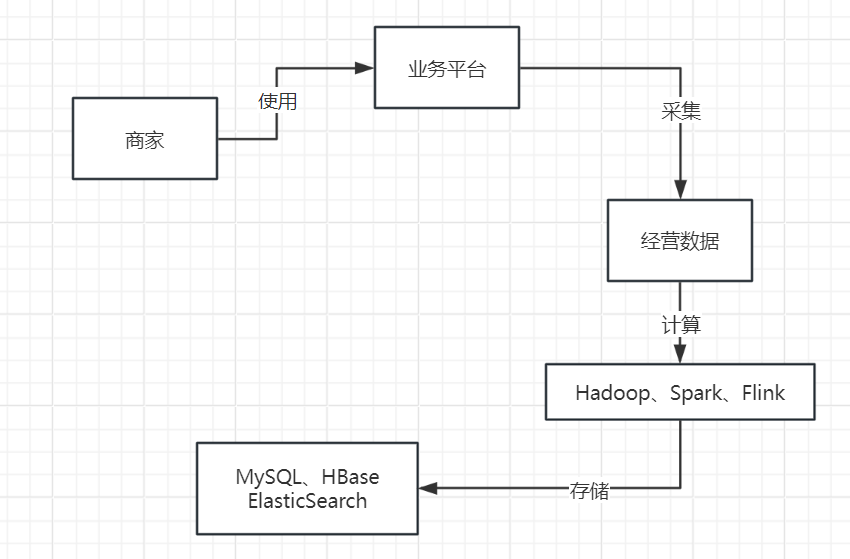
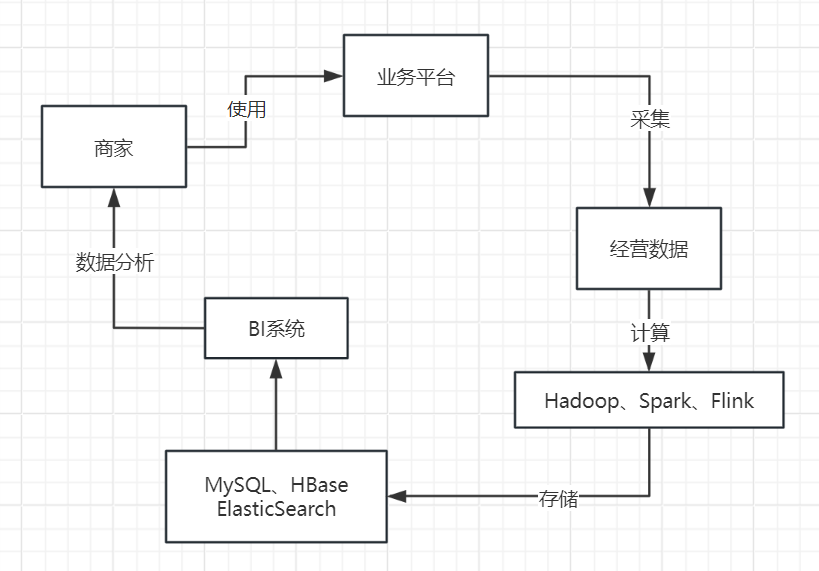
最后一步,就是基于MySQL、HBase、Elasticsearch中存储的数据报表,基于Java开发出来一个BI系统,通过这个系统把各种存储好的数据暴露给前端,允许前端基于各种条件对存储好的数据进行复杂的筛选和分析,如下图所示。
3、探秘新系统上线之初的高效架构设计
在本次案例分析中,我们将重点讨论的是上述场景中的BI(Business Intelligence)系统。在BI系统刚开始投入使用时,使用它的商家并不多。这是因为在一个庞大的互联网大厂中,尽管大厂本身已经积累了大量的商家资源,但是当针对他们推出一个付费产品时,一开始并不是所有商家都愿意接受。因此,在初始阶段,只有少数商家在使用这个系统,例如大约几千个商家。
鉴于这种情况,系统部署非常简单,仅使用了数台机器来部署上述的BI系统。这些机器都是普通的4核8G配置。在这个配置下,通常为堆内存中的新生代分配的内存约为1.5G,而Eden区的空间大约为1G左右。如下图所示。
4、技术痛点:实时自动刷新报表 + 大数据量报表
在最初阶段,当商家的数量相对较少时,这个系统的运行表现是相当出色的,没有出现任何显著的问题。然而,随着使用该系统的商家数量的急剧增加,问题开始显现。
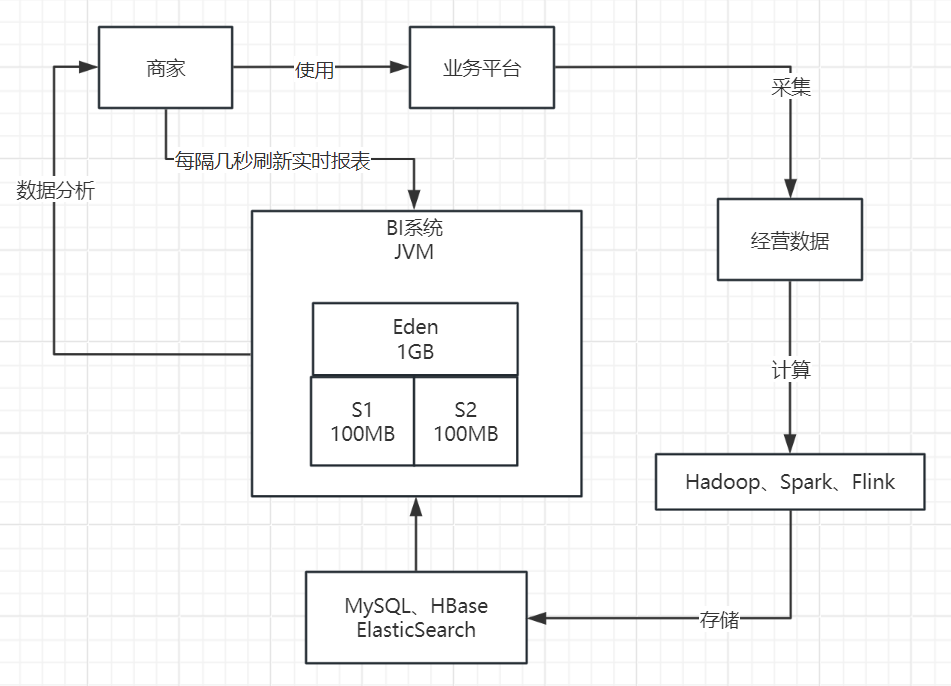
举个例子,当使用系统的商家数量突然增加到数万的时候,系统的性能就开始出现问题。这主要是因为,这种BI(商业智能)系统的一个特性是,它支持一种叫做“实时数据报表”的数据报告。这种报告的特点是,它会在前端页面上运行一个JS脚本,这个脚本每隔几秒钟就会向后端发送请求,以刷新报告中的数据。
因此,当大量的商家开始使用这个系统时,这种频繁的请求就会对系统的性能造成压力,导致系统出现问题。这就是我们在商家数量激增时遇到的问题,我们需要对此进行优化和改进,以确保系统能够稳定高效地运行。如下图所示。
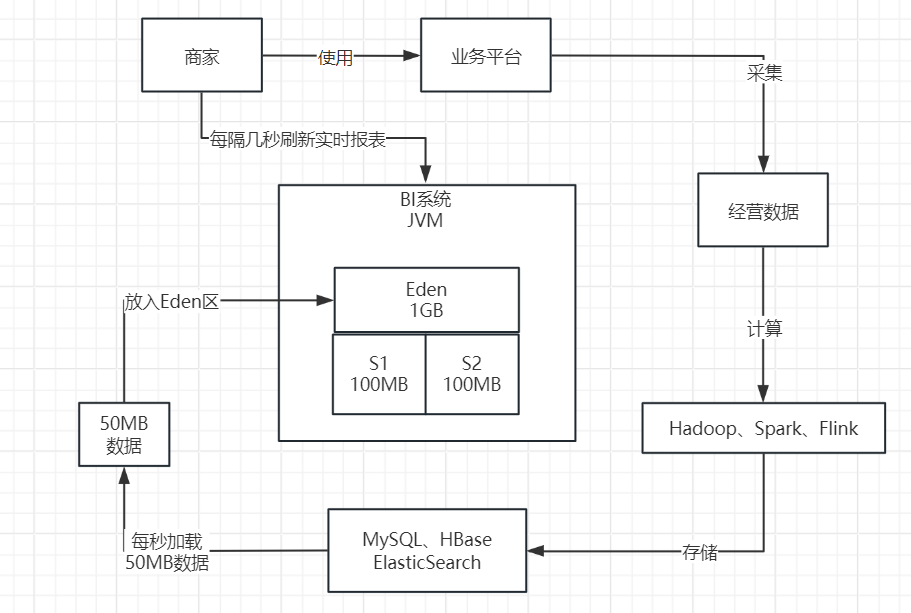
让我们来想象一个场景,假设有数万商家使用你的系统。在高峰时段,很可能同时有数千家商家正在查看实时报表。
当这些商家打开实时报表时,他们的前端页面会每隔几秒钟向后台发送请求,以获取最新数据。这意味着,你的BI(商业智能)系统的每台服务器可能会在每秒收到数百个请求,我们可以假设大约是500个请求。
每个请求都会加载大量数据,因为BI系统需要对数据进行内存计算和处理,然后才能返回给前端页面进行展示。
根据我们的估算,每个请求大约需要加载100KB的数据进行处理。因此,如果每秒有500个请求,那么就需要将50MB的数据加载到内存中进行计算。如下图所示。
5、没什么大影响的频繁Young GC
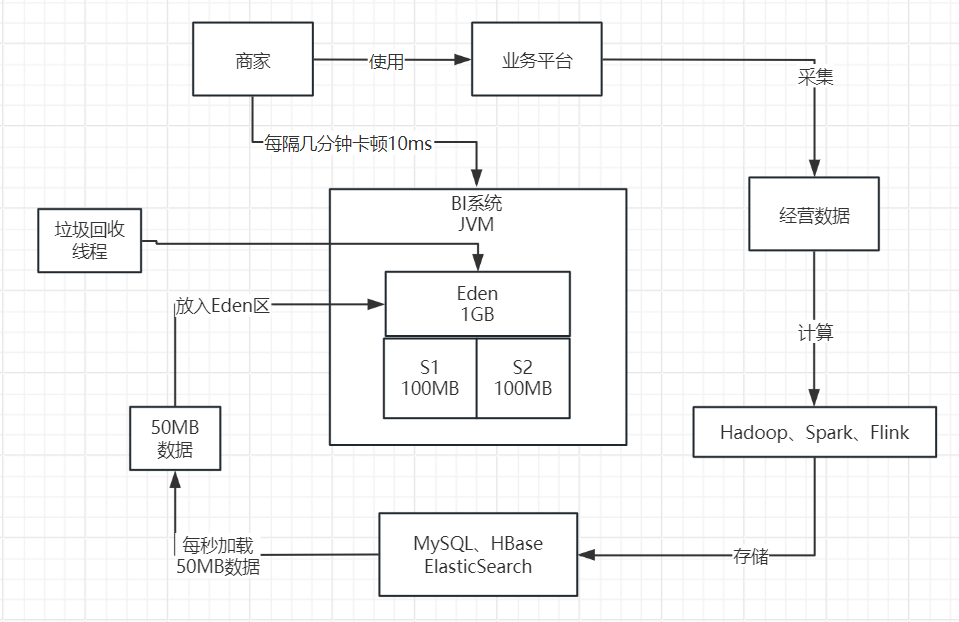
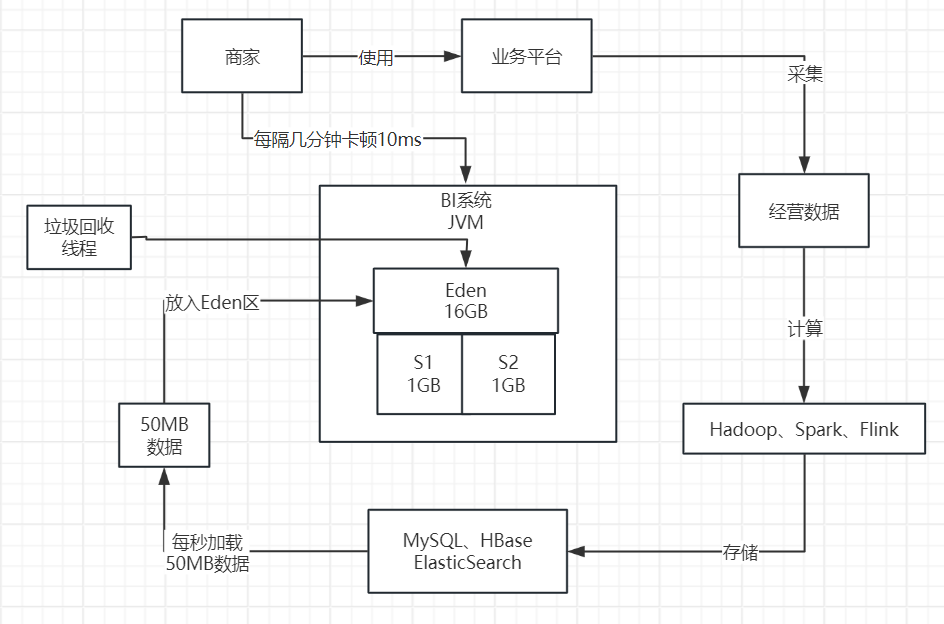
其实大家都已经发现上述系统的问题了。在上述系统运行模型下,基本上每秒会加载50MB的数据到Eden区中。只要短短的200秒,也就是3分钟左右的时间,就会迅速填满Eden区,然后触发一次Young GC对新生代进行垃圾回收。
当然,1G左右的Eden进行Young GC,其实速度相对是比较快的,可能也就几十毫秒的时间就可以搞定了。所以之前也分析过,其实对系统性能影响并不大。而且,在上述BI系统场景下,基本上每次Young GC后存活对象可能就几十MB,甚至是几MB。
所以,如果仅仅只是这样的话,那么大家可能会看到如下场景:BI系统运行几分钟过后,就会突然卡顿个10毫秒,但是对终端用户和系统性能几乎是没有影响的。
如下图。
6、提升机器配置:运用大内存机器
随着越来越多的商家开始使用这套系统,系统的并发压力逐渐增大,甚至在高峰期会达到每秒10万的并发压力。想象一下,如果仍然使用4核8G的机器来支持这样的高并发压力,我们可能需要部署上百台机器来应对。
为了解决这个问题,我们决定提升机器的配置。考虑到BI系统对内存的需求较高,我们将部署的机器配置提升到了16核32G的高配置。每台机器现在可以承受每秒几千个请求,因此我们只需要部署二三十台机器即可。
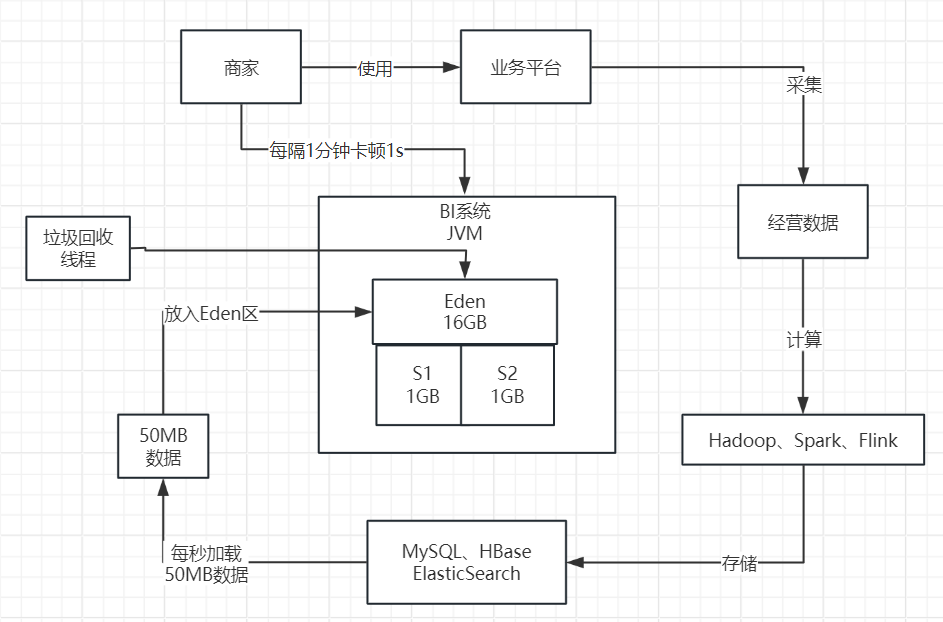
然而,此时又出现了一个问题。当我们使用大内存机器时,新生代至少需要分配到20G的大内存,而Eden区也需要占据16G以上的内存空间。此时如下图所示。
在面对每秒数千次的请求时,系统会将大约几百MB的数据加载到内存中。这样的数据处理速度,可能在几十秒,甚至1分钟左右就会将Eden区填满,进而触发Young GC(年轻代垃圾回收)。
在这种情况下,Young GC需要处理大量的内存数据,这将会显著地降低其运行速度。因此,可能引发系统的卡顿,这种卡顿可能会持续几百毫秒,或者达到1秒钟。如下图所示。
如果您的系统卡顿时间过长,那么很自然地,这将导致大量的请求在短时间内堆积并排队等候处理。在严重的情况下,这种积压可能会导致线上系统的不稳定,表现为前端请求超时的问题。具体来说,当用户发起一个请求,如果在一两秒钟后系统还没有响应,前端就会因为超时而报错。这种情况会严重影响用户体验,因此确保系统能够快速响应是至关重要的。
7、使用G1技术提升大内存设备的垃圾收集效率
为了优化这个系统,我们采用了G1垃圾回收器来解决大内存情况下Young GC过慢的问题。通过对G1设置一个预期的GC停顿时间,例如100毫秒,我们可以确保每次Young GC的停顿时间最多为100毫秒,从而避免对终端用户的使用造成影响。
这种优化策略的效果非常显著。G1会自动控制每次Young GC时回收一部分Region,以确保GC停顿时间保持在100毫秒以内。尽管这可能会导致Young GC的频率略有增加,但由于每次停顿时间非常短暂,对系统的整体影响将大大减小。
通过采用G1垃圾回收器并合理设置预期的GC停顿时间,我们能够有效地解决大内存情况下Young GC过慢的问题,提升系统的性能和用户体验。
8、本文总结
本文通过一个实际案例,旨在阐述一个观点:通常来说,即便Young GC(年轻代垃圾回收)发生得较为频繁,对系统的运行影响也相对有限。
然而,当计算机的内存规模特别大时,需要注意的是,Young GC可能会引发较长时间的系统停顿。在这种情况下,对于大内存机器,我们通常建议采用G1垃圾回收器。
G1垃圾回收器是一种面向大内存机器的垃圾回收器,它能够有效地减少系统停顿时间,提高系统性能。在处理大内存机器时,G1垃圾回收器可以更好地平衡垃圾回收的负载,避免出现长时间的停顿,从而确保系统的稳定运行。
因此,如果你的机器拥有较大的内存,并且希望减少系统停顿时间,考虑采用G1垃圾回收器是一个值得考虑的选择。